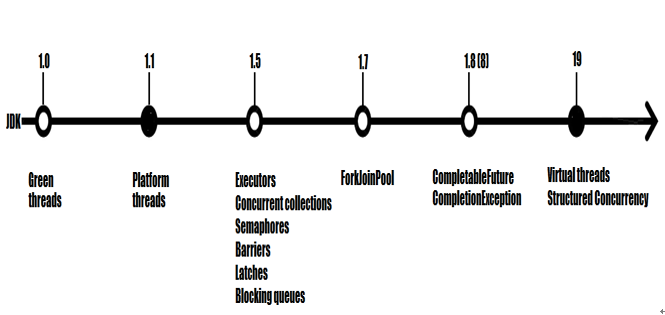
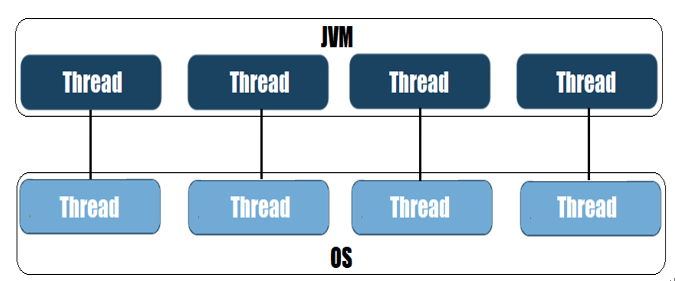
- Certification Exams of Java Explaining how virtual threads work Introducing virtual threads Java Certification Exams Technical requirements The benefits of cloud architecture Understanding cloud architecture
- Posted By

Introducing structured concurrency 2 – Concurrency – Virtual Threads, Structured Concurrency
We skip the rest of the code since you can find it in the bundled code.Of course, we can implement code-answers to each of these questions via error handling, tasks abandon and abortion, ExecutorService, and so on, but this means a lot of work for the developer. Writing failsafe solutions that carefully cover all possible scenarios across multiple tasks/subtasks while tracking their progress in a concurrent environment is not an easy job. Not to mention how hard is to understand and maintain the resulting code by another developer or even the same developer after 1-2 years or even months.It is time to add some structure to this code, so let’s introduce structured concurrency (or, Project Loom).Structured concurrency relies on several pillars meant to bring lightweight concurrency in Java. The fundamental pillar or principle of structured concurrency is highlighted next.
The fundamental principle of structured concurrency: When a task has to be solved concurrently then all the threads needed to solve it are spun and rejoined in the same block of code. In other words, all these threads’ lifetime is bound to the block’s scope, so we have clear and explicit entry-exit points for each concurrent code block.
Based on this principle, the thread that initiates a concurrent context is the parent-thread or the owner-thread. All threads started by the parent-thread are children-threads or forks, so between them, these threads are siblings. Together, the parent-thread and the children-threads, define a parent-child hierarchy.Putting the structured concurrency principle in a diagram can be seen as follows:
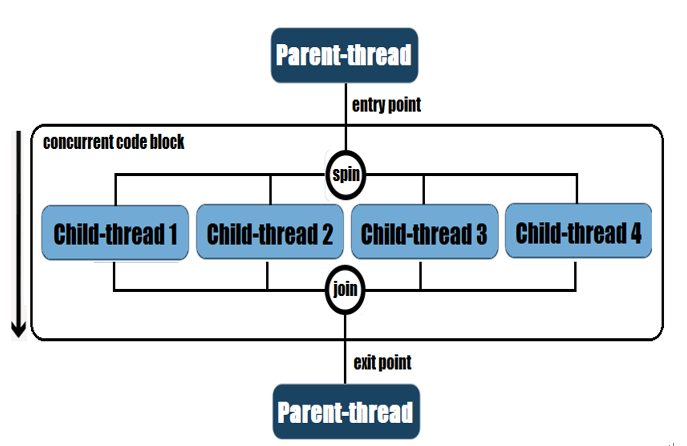
Figure 10.2 – Parent-child hierarchy in structured concurrency
In the context of parent-child hierarchy, we have support for error/exception handling with short-circuiting, cancellation propagation, and monitoring/observability.Error/exception handling with short-circuiting: If a child-thread fails then all child-threads are canceled unless they are complete. For instance, if futureTester(1) fails, then futureTester(2) and futureTester(3) are automatically canceled.Cancellation propagation: If the parent-thread is interrupted until joining the child-threads is over then these forks (the child-threads/subtasks) are canceled automatically. For instance, if the thread executing buildTestingTeam() gets interrupted then its three forks are automatically canceled.Monitoring/observability: A thread dump reveals crystal-clear the entire parent-child hierarchy no matter how many levels have been spawned. Moreover, in structured concurrency, we take advantage of scheduling and memory management of threads.While these are purely concepts, writing code that respects and follows these concepts requires the proper API and the following awesome callout:

Figure 10.3 – Don’t reuse virtual threads
Cut this out and stick it somewhere to see it every day! So, in structured concurrency, don’t reuse virtual threads. I know what you are thinking: hey dude, threads are expensive and limited, so we have to reuse them. A quick hint: we are talking about virtual threads (massive throughput), not classical threads, but this topic is covered in the next problem.